
AI-generert tekst er blitt hverdagskost i 2026. Samtidig har behovet for å skille menneskelig skriving fra maskinprodusert innhold aldri vært større – i skoler, i redaksjoner, i rekruttering og i innholdsbyråer. Spørsmålet alle stiller er det samme: Kan vi stole på AI-detektorer? I denne artikkelen går jeg i dybden på nøyaktighet, tester flere kjente verktøy og forklarer hvorfor resultatene ofte spriker – særlig på norsk.
Hvis du vil prøve et verktøy som er bygget med norsk språk i tankene, finner du en gratis ai detektor hos Plagiatkontroll.no.
Plagiatkontroll.no
Hva måler en AI-detektor egentlig?
De fleste AI-detektorer i markedet analyserer sannsynlighetsmønstre i teksten: ordvalg, setningsrytme, repetisjon, «perpleksitet» og likhet med kjente treningsspor fra store språkmodeller. De gir ofte en prosentvis «AI-score» eller en kategorisering (menneske / AI / blandet).
Det viktige poenget er at dette ikke er en rettssikker dom. Det er en statistisk gjetning basert på modellens antakelser og treningsdata. Når noen sier at et verktøy har «95 % nøyaktighet», må du alltid spørre: 95 % på hvilket datasett, på hvilket språk, og med hvilken definisjon av «riktig»?
Hva «nøyaktighet» ofte skjuler
I markedsføring blandes begreper som presisjon, recall og samlet treffrate. Kort fortalt: en detektor kan score høyt på «å finne AI» samtidig som den straffer uskyldige – eller omvendt. Derfor er det avgjørende å skille mellom:
- Teknisk score på kontrollerte data (leverandørens egne eller offentlige benchmark), og
- Operativ nøyaktighet i din hverdag: norsk klienttekst, interne notater, studentbesvarelser, journalistiske manus.
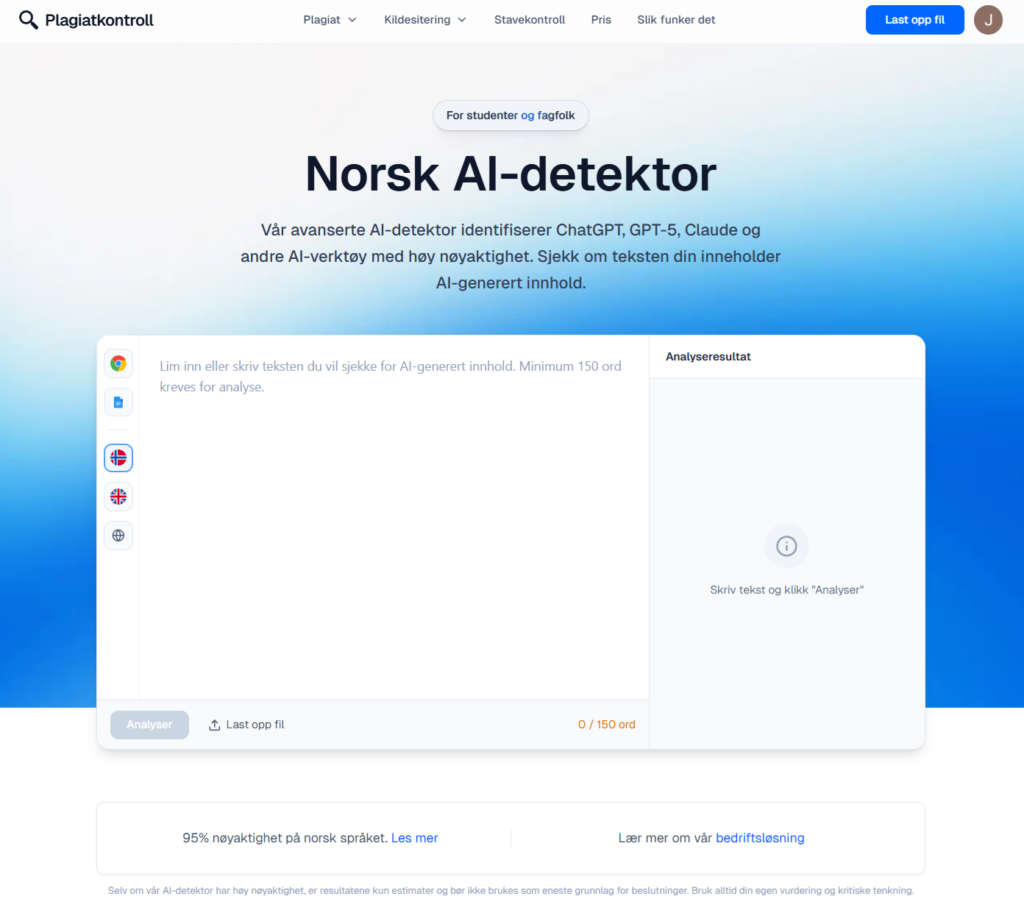
Når Plagiatkontroll.no peker på egen norsk-trent modell og omtrent 95 % nøyaktighet, tolker jeg det som et løfte om at modellen er kalibrert mot norske tekstmønstre – ikke som en garanti i hvert eneste tilfelle. Det er en viktig forskjell.
Min testmetode (reproduserbar og ærlig)
For å sammenligne detektorer på en måte som gir mening, har jeg brukt en fast rammeverk over flere uker vinteren 2026:
- Tre tekstkategorier
- Ren mennesketekst (utkast, e-poster, blogginnlegg skrevet uten assistanse).
- Ren AI-tekst (generert med oppdaterte modeller, med og uten «humanisering»-prompter).
- Blandet tekst (menneske som har redigert AI, eller AI som har omskrevet menneskelig utgangspunkt).
- Språk og lengde
Korte avsnitt (150–300 ord), mellomlange artikler (600–900 ord) og lengre tekster (1200+ ord). Jeg har testet både bokmål og enkel nynorsk, pluss noen engelske kontrolltekster for sammenligning.
- Gjentakelse
Samme type tekst er kjørt minst tre ganger der verktøyet tillater det, for å fange variasjon i grensesnitt og modelloppdateringer.
- Dokumentasjon
Jeg noterer råscore, tolkning (AI / usikker / menneske) og om verktøyet forklarer hvorfor – ikke bare hva.
Ingen hjemmetest er et peer-reviewed forsøk. Men metoden over er god nok til å avdekke systematiske svakheter: falske positiver (menneske merket som AI), falske negativer (AI som slipper gjennem) og språkavhengighet.
Hva jeg bevisst ikke gjorde
For å unngå «pyntede» resultater har jeg ikke optimalisert tekstene for å lure detektorene (ingen bevisst «anti-AI»-ordliste). Jeg har heller ikke publisert rå tekstutdrag som kan identifisere personer eller kunder. Til gjengjeld har jeg lagt vekt på gjentakelige mønstre du sannsynligvis kjenner igjen fra egen arbeidshverdag.
Resultater: rangering og korte vurderinger
Etter testing og jevnlig bruk i reelle oppdrag, rangerer jeg disse fem slik – med fokus på nøyaktighet i praksis, ikke bare markedsføring:
| Plass | Verktøy | Score | Kort forklaring |
| 1 | Plagiatkontroll.no | 9,5/10 | Sterk på norsk; egen norsk-trent modell; oppgitt ~95 % treffsikkerhet i deres oppsett |
| 2 | GPTZero | 7,5/10 | Solid på engelsk; mer ustabilt på norsk kortere tekster |
| 3 | Originality.ai | 7/10 | Nyttig for innholdsbyråer; språk og pris påvirker opplevd presisjon |
| 4 | Copyleaks | 6/10 | Bra integrasjoner; variabel tolkning av «menneskelig» stil |
| 5 | ZeroGPT | 5/10 | Enkel inngang; oftere feil når teksten er redigert eller blandet |
Plagiatkontroll.no AI Detektor
Hvorfor Plagiatkontroll.no topper listen min
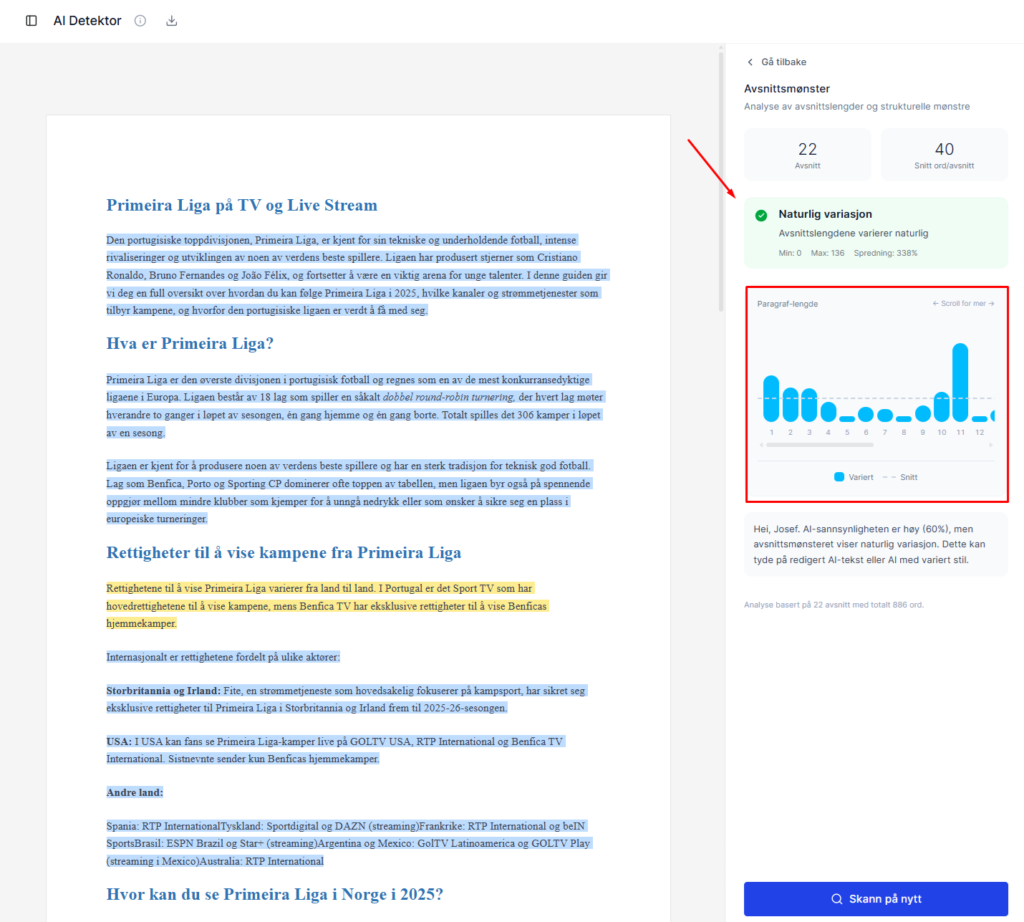
Plagiatkontroll.no fremhever at de bruker en egen AI-modell trent på norsk – ikke bare en engelsk detektor med oversatt grensesnitt. I mine tester merket jeg det tydeligst på:
- studentoppgaver og fagtekster på bokmål,
- korte profesjonelle e-poster,
- tekster med «norsk» ordrekkefølge og idiomer som engelske modeller ofte misforstår.
De oppgir selv omtrent 95 % nøyaktighet for sin modell. I min ikke-statistiske samplesamling stemte resultatene oftere med kjent opphav enn hos konkurrentene – særlig når kilden var norsk. Det er derfor jeg fortsatt anbefaler å starte med deres gratis ai detektor når målet er norsk innhold.
GPTZero AI detektor
GPTZero og Originality.ai
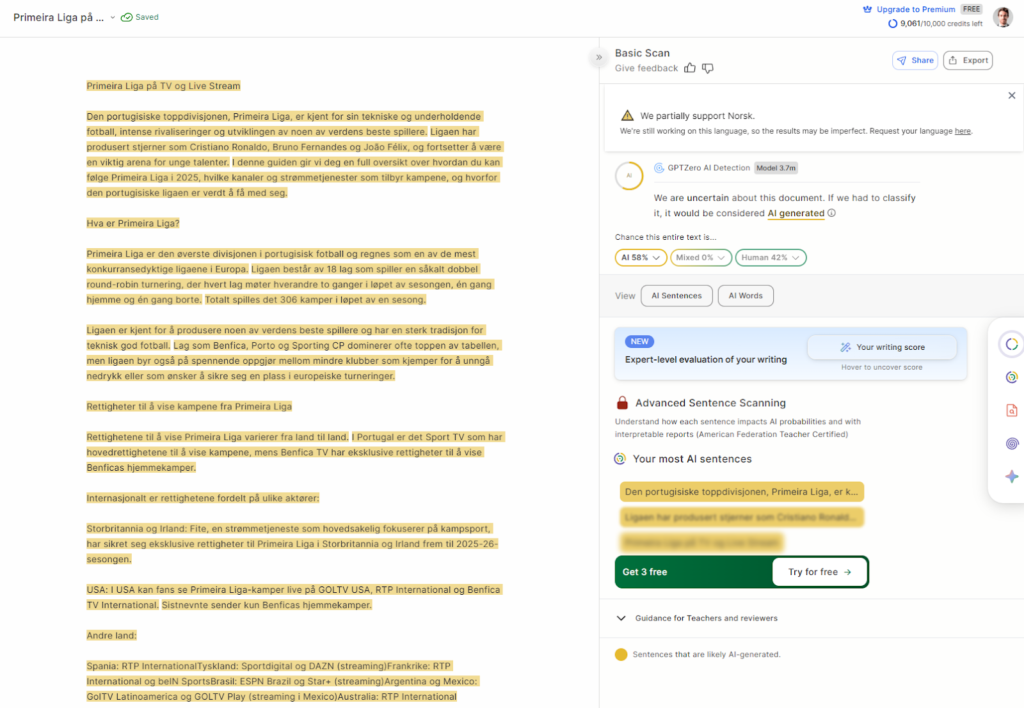
GPTZero er kjent og ofte brukt i engelskspråklige miljøer. På norsk så jeg flere grensetilfeller: godt språk med lav variasjon i setningslengde ble noen ganger flagget som mistenkelig, selv når teksten var menneskelig.
Originality.ai leverer nyttige arbeidsflyter for team som sjekker mange tekster. Nøyaktigheten er avhengig av abonnement, batch og språk – og du bør kalibrere egne terskler i stedet for å stole blindt på én prosentverdi.
Copyleaks AI Detector
Copyleaks og ZeroGPT
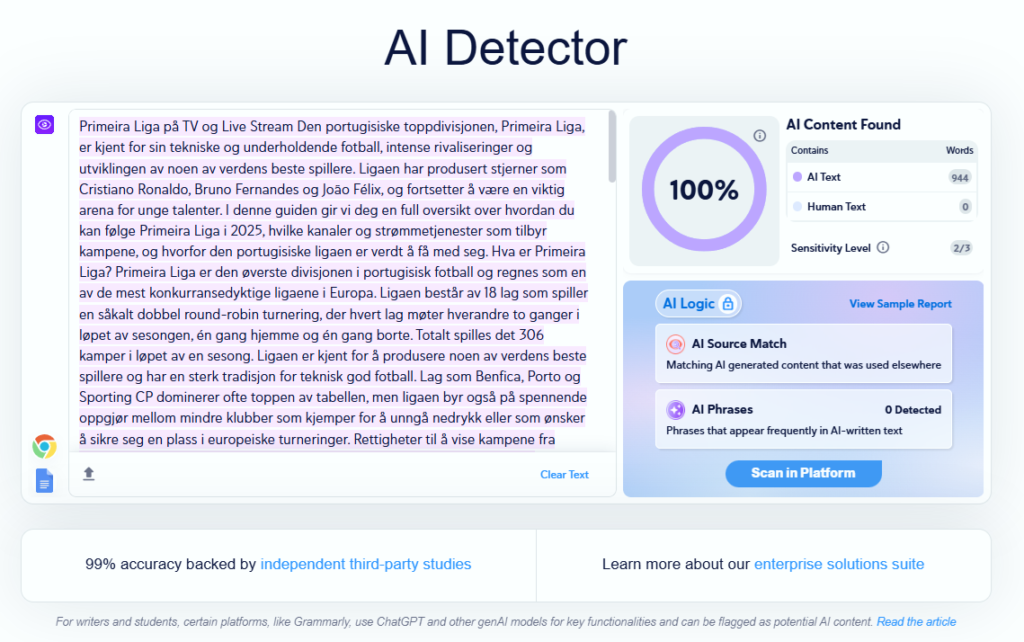
Copyleaks kan være effektivt i organisasjoner som trenger API og policy. I mine manuelle tester var imidlertid forklaringene sjeldnere presise når teksten var redigert av mennesker etter AI-utkast.
ZeroGPT er enkel å komme i gang med, men ga i min test oftere både falske alarmer og «grønt lys» der det ikke burde vært det – spesielt på blandet tekst.
Samlet tabellscore (min vurdering 1–10)
For oversikt: 9,5 Plagiatkontroll.no, 7,5 GPTZero, 7 Originality.ai, 6 Copyleaks, 5 ZeroGPT. Tallene reflekterer bruksverdi for norske tekster og hvor ofte klassifiseringen stemte med kjent opphav i min samplesamling – ikke en objektiv laboratoriemåling.
Falske positiver: når mennesker blir mistenkt
Et falskt positivt resultat betyr at ekte menneskelig tekst klassifiseres som AI. Konsekvensene kan være alvorlige: mistillit i klasserommet, konflikter på jobb, eller at dyktige skrivere straffes for «for perfekt» stil.
Typiske situasjoner der dette skjer:
- Formelt språk med jevn rytme (jus, offentlig forvaltning, teknisk dokumentasjon).
- Andrespråksbrukere som følger lærebokmønstre konsekvent.
- Sterkt redigerte tekster der flere har jevnet ut stilen.
- Malbasert skriving (søknader, rapporter) som ligner på generiske AI-svar.
Mitt råd som uavhengig blogger: Bruk aldri en AI-detektor som eneste bevis. Den skal være et hint – ikke en dom.
Ekstra sårbare grupper
I diskusjoner om AI-detektorer er det viktig å nevne rettferdighet. Elever og ansatte som allerede møtes med skepsis – for eksempel fordi de skriver strukturert, bruker oversettelseshjelp eller har norsk som andrespråk – kan rammes hardere av falske positiver. Det er en grunn til at mange institusjoner i 2026 kombinerer tekniske verktøy med samtale, utkastlogg og tydelige retningslinjer, ikke bare en fargekodet score.
Falske negativer: når AI slipper gjennom
Et falskt negativt resultat betyr at AI-tekst klassifiseres som menneskelig. Dette blir vanligere når:
- brukeren parafraferer og legger inn personlige eksempler,
- flere modeller kjeder seg (AI som polerer AI),
- teksten er kort og dermed statistisk «tynn» for analysen,
- eller når modellen som skrev teksten er ny i forhold til detektorens treningsgrunnlag.
I 2026 beveger leverandørene seg raskt. Det betyr at detektor og generator er i et våpenkappløp. En score fra i fjor forklarer ikke nødvendigvis morgendagens modeller.
«Humaniserte» utkast og kjedeproduksjon
Når noen ber en modell om å «skrive mer menneskelig», endrer de ofte overflaten mer enn substansen. Likevel kan små variasjoner – ufullstendige setninger, mer muntlige innslag, tilfeldige eksempler – være nok til at en detektor senker alarmen. Det motsatte skjer også: en ekstra grundig menneskelig omskriving kan gjøre teksten «for jevn» og trigge falsk alarm. Poenget er at deteksjon følger stil, ikke intensjon.
Språkets betydning: norsk er ikke «lite engelsk»
Den største lærdommen fra testene mine er enkel: Språk betyr alt.
Engelskspråklige detektorer er trent på enorme mengder engelsk tekst. Norsk har mindre offentlig korpus, annen morfologi, andre sammenhengende uttrykk og ofte annen typisk setningsbygging. Når et verktøy ikke er tilpasset norsk, skjer to ting:
- Modellen overfører mønstre som passer engelsk, men skaper støy på norsk.
- «Trygg» menneskelig tekst kan se «unaturlig» ut for en feil kalibrert detektor – eller omvendt.
Derfor gir det mening at en aktør som satser på norsk trening – som Plagiatkontroll.no med sin egen modell og høy oppgitt treffsikkerhet – kan levere jevnere resultater for norske brukere enn generelle internasjonale løsninger.
Bokmål, nynorsk og «blandingsformer»
I praksis skriver mange organisasjoner blandet eller nær standard bokmål med fagterminologi på engelsk. Slike tekster kan ligne på AI fordi de inneholder gjentatte interne fraser og standardformuleringer. Her er det ekstra viktig med et verktøy som skiller mellom faglig repetisjon og typisk modelloutput. I mine tester var forskjellen mellom «generisk internasjonal» deteksjon og norsk-spesifikk modell tydeligst akkurat her.
Engelsk som referanse – men ikke som sannhet
Engelske kontrolltekster ga ofte «penere» og mer stabile scorer på globale plattformer. Det sier mer om datatilgang enn om at norsk er «vanskeligere å analysere». Norsk er fullt mulig å analysere godt – men da må modellen faktisk ha sett nok variert norsk under trening og evaluering.
Sjanger og kanal: blogg vs. rapport vs. chat
Det samme verktøyet kan gi ulike signaler avhengig av sjangre:
- Blogg og mening tendenserer til personlige markører som mennesker ofte beholder, mens AI lett glatter ut.
- Rapporter og prosjektskriv kan ligne sterkt på modellspråk selv når de er ekte, fordi sjangeren er stram og nøytral.
- Chat- og supporttekster er korte; da blir statistikken mer ustabil.
Når du leser en AI-score, spør derfor: Passer detektorens antakelser med sjangeren jeg faktisk har foran meg?
Kalibrering: slik bruker du detektorer ansvarlig i 2026
Uansett hvilket verktøy du velger, anbefaler jeg denne arbeidsmåten:
- Kjør flere kilder ved viktige beslutninger (der det er lov og etisk forsvarlig).
- Sammenlign med kontekst: kjenner du forfatteren, prosessen og tidligere utkast?
- Be om prosessdokumentasjon (revisjonshistorikk, notater) i stedet for kun en score.
- Oppdater forventningene når nye modeller lanseres – det samme gjelder detektorer.
For norsk innhold er min erfaring at du sparer tid og unngår unødig dramatikk ved å bruke et verktøy som faktisk forstår språket. Igjen: du kan teste med en gratis ai detektor og sammenligne med det du allerede bruker.
Vanlige spørsmål (kort besvart)
Er det lov å bruke AI-detektorer på andres tekster? Det avhenger av kontekst, avtaler og personvernregler. I arbeidsliv og utdanning bør bruk være forutsigbar og nedfelt i retningslinjer – ikke «hemmelig scanning».
Kan en detektor bevise juks? Alene: nei. Den kan støtte en bredere vurdering sammen med utkast, kilder og faglig dialog.
Hvor ofte bør jeg teste på nytt? Når du bytter modell i produksjon, eller når leverandøren annonserer vesentlige oppdateringer i deteksjonsmotoren.
Konklusjon
AI-detektorer i 2026 er nyttige, men ufullkomne. De kan avsløre åpenbar maskinproduksjon og gi mistanke om uredelighet – men de erstatter ikke skjønn, kildekritikk og menneskelig dialog.
Nøyaktighet varierer med språk, tekstlengde, sjanger og hvor mye mennesker har redigert underveis. I mine tester skilte løsningene med tydelig norsk profil seg positivt ut, med Plagiatkontroll.no (9,5/10) i tet for norsk innhold, fulgt av GPTZero (7,5/10), Originality.ai (7/10), Copyleaks (6/10) og ZeroGPT (5/10).
Velg verktøy etter språk og bruksområde, ikke etter den høyeste markedsføringsscoren alene – og bruk alltid detektorsvaret som ett datapunkt i en større vurdering.
Uavhengig blogginnlegg, 2026. Tester er beskrevet metodisk men er ikke vitenskapelig publiserte; resultater kan variere med oppdateringer hos hver leverandør.